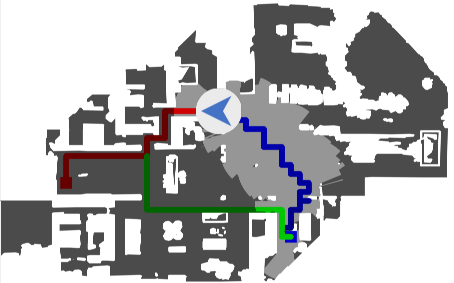
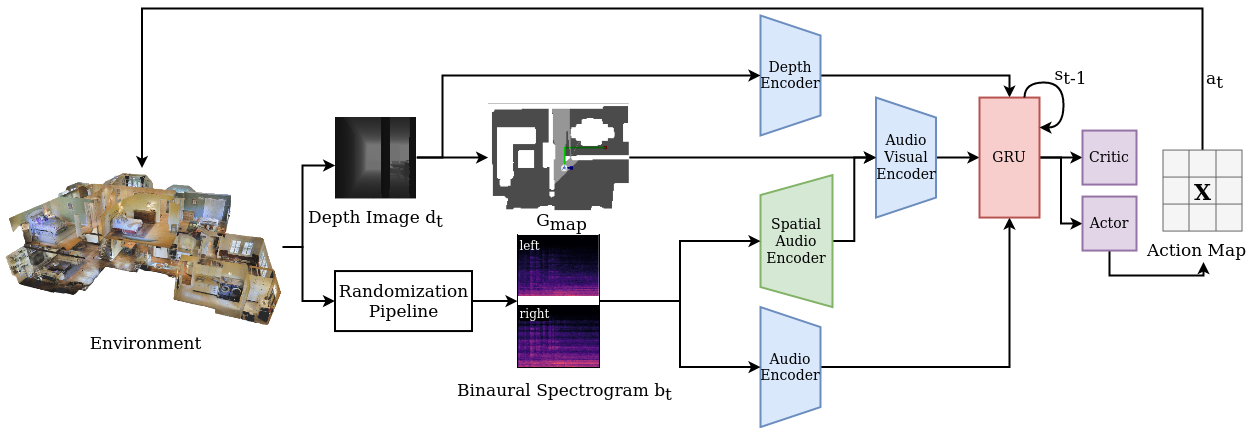
Audio-visual navigation combines sight and hearing to navigate to a sound-emitting source in an unmapped environment. While recent approaches have demonstrated the benefits of audio input to detect and find the goal, they focus on clean and static sound sources and struggle to generalize to unheard sounds. In this work, we propose the novel dynamic audio-visual navigation benchmark which requires to catch a moving sound source in an environment with noisy and distracting sounds. We introduce a reinforcement learning approach that learns a robust navigation policy for these complex settings. To achieve this, we propose an architecture that fuses audio-visual information in the spatial feature space to learn correlations of geometric information inherent in both local maps and audio signals. We demonstrate that our approach consistently outperforms the current state-of-the-art by a large margin across all tasks of moving sounds, unheard sounds, and noisy environments, on two challenging 3D scanned real-world environments, namely Matterport3D and Replica.
Catch Me If You Hear Me: Audio-Visual Navigation in Complex Unmapped Environments with Moving Sounds
Abdelrahman Younes, Daniel Honerkamp, Tim Welschehold, Abhinav Valada